.well-known crawler
Crawl well-known Resources introduced by The Privacy Sandbox:
-
/.well-known/privacy-sandbox-attestations.json- Submit a form, JSON file sent by Google
- No public list of who participates
- Crawler: https://github.com/privacysandstorm/well-known-crawler
- Post-analysis: https://github.com/privacysandstorm/well-known-crawler-analysis
Datasets for this crawler are stored on Amazon S3 in requestor pays buckets. This means that you must pay API call and data transfer rates associated with downloading the data. All datasets are stored in the us-east-2 region, so you can avoid data transfer fees by performing analysis within this region.
Data is stored in one of two buckets depending on the nature of the data:
s3://well-known-crawler-data- raw crawl data are stored within this bucket. You may use any AWS IAM account to download from this bucket.s3://well-known-crawler-analysis- analysis artifacts are stored within this bucket. You may use any AWS IAM account to download from this bucket.
The crawl automatically runs twice per month as a minimum followed by the post analysis. You can always access the most up-to-date version of the results at the following URLs (in addition to in the buckets above):
- List of origins with an
/.well-known/related-website-set.jsonfile: https://privacysandstorm-public-data.s3.us-east-2.amazonaws.com/well-known-crawler/rws_known_origins.json - List of origins with an
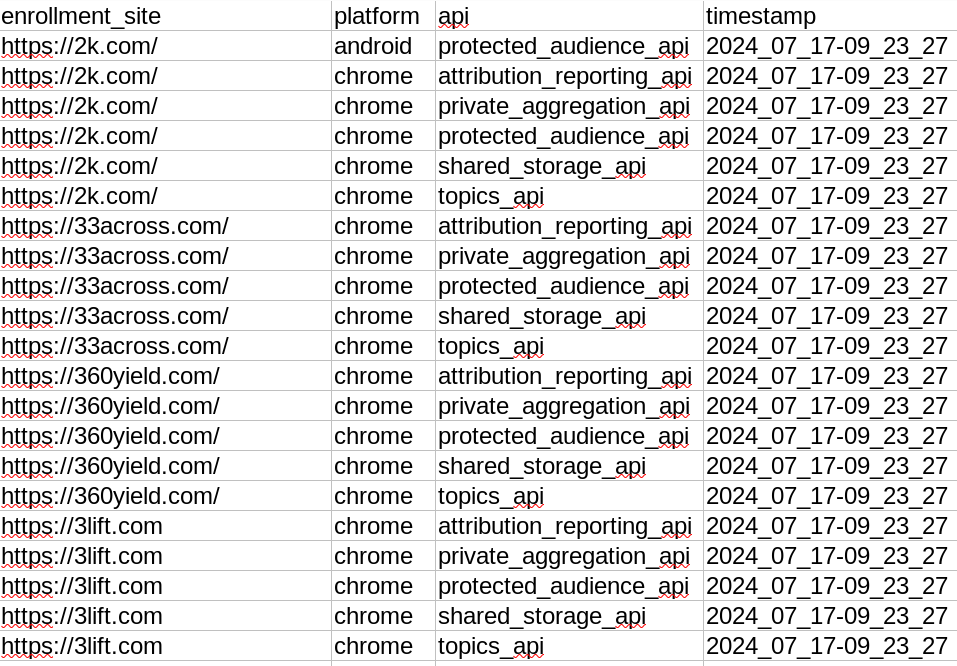
/.well-known/privacy-sandbox-attestations.jsonfile: https://privacysandstorm-public-data.s3.us-east-2.amazonaws.com/well-known-crawler/attestation_known_origins.json - Generated list of enrollment sites and corresponding APIs: https://privacysandstorm-public-data.s3.us-east-2.amazonaws.com/well-known-crawler/attestation_known_apis.tsv